Connect with me
MCP Matters! Streamlining AI’s Interaction with Data
Every now and then, the tech world has a habit of spinning up some new technology that seems revolutionary and allegedly humanity-changing.
As you know, LLM-based AI is one such technology that has been in the news quite a bit recently — so much so that it is also influencing the military and political landscapes of major countries like China and the USA.
On an industrial level, the recent surge of LLMs (Large Language Models) has changed the perception of how things have been done in the past. The ability of LLMs to generate media holds vast potential to influence nearly every kind of knowledge work we do, across all industries.
However, when the entire industry across multiple domains is set to use something like LLMs, the future will benefit from having standards in place for developing AI applications that work with our data.
Even though, LLMs are intelligent models and their knowledge is increasing everyday as the world giants like OpenAI aims for AGI, but their domain knowledge is still remains limited for the time being. And that’s why, LLMs are more useful when integrated and used with our data and knowledge.
As the software engineering world mostly communicates in the language of standards and specifications, MCP, or Model Context Protocol, is yet another standard in the world of Artificial Intelligence and LLMs, aimed at standardizing the way LLMs and AI applications interact with data sources.
Need for a standardized way of working with data sources
When the LLMs market started getting bigger, we saw the rise of so many proprietary, commercial, and open-source models. Nearly every software manufacturer started developing wrapper applications on top of these models calling them agents, tools, services etc.
❌ LLMs on their own cannot produce knowledge; they can only generate knowledge based on the data they were initially trained on. So, if a developer is creating an application in a particular domain, they’ll have to provide the data to the LLM so that these LLMs can then generate answers, text, or media that is more suitable for the use.
The way to plug in the information that may be required by LLMs to generate answers is to create an information system, similar to a search engine or a catalogue. This system will be designed to fetch information directly from our data source, which could be of any type.
A data source can be anything. It can be a relational database, loose text files, a binary blob, a video file, etc. But in order to fetch data from this source, we would primarily need to write a module that will handle working with this data source and providing data to our AI application needs.
For example, let’s suppose we have a database of purchases made by regular customers in a clothing shop each week. We want to create an LLM application that reads this data and generates a summary report of all the merchandise sold in a week. To create such a service, the LLMs would first need this data in text format along with a prompt.
Our databases stores the data in rows and columns and can only be read with SQL queries. Hence, we design a simple retrieval system that can gather the data from this database in row-column format and then convert this data into text format, which can thus be consumed by LLM services to generate the reports.
Creating a retrieval layer so that an LLM can use the data from our data source is not a challenge but the bottleneck is that nearly every AI application developer on this planet is creating their own retrieval and data-source layer!
Imagine there are M LLMs available on this earth, and the developer community as a whole has created N retrieval systems for their data sources. Then, to have AI applications that can work with all data sources and all available LLM services, we would need M × N integrations. This means, let’s say, if I want to use both GPT and Claude models on my data source, I need to configure and maintain 2 AI applications. Additionally, if I introduce one more data source, that number grows to 4 AI applications. This becomes a major problem in the longer run.
Also, it does not make sense for developers to create their custom systems like these for the same kinds of data sources. For example, Google might develop a retrieval layer for their implementation of a PostgreSQL database, and Microsoft could do the same. Oracle might create a retrieval layer for PDF-based data sources, and yet SAP would also build a similar solution which is totally unecessary!
So, how do we reduce the M × N problem to an M + N problem? Meaning, even if the model changes, the data source can be used interchangibliy like plug-and-play.
And that’s where MCP introduce a standard architecture for both LLM and data manufacturers.
How would MCP work?
Before getting started with MCP, we should look a little more into what our data comprise in context of an AI application.
When we talk about building an AI application many a times a simple data access is not sufficient. The granularity of data access matters. Additionally, we also need representation of atomic units in data which can be resources, roots etc.
A prompt can also be a data source which is kept to standardize the response that has to be generated by the LLM and is of concern the data source manufacturer.
👉 All of this access to the data source is well structured in the component called “MCP Server”, which is then used by “MCP Client” component from the LLM’s or AI application end to consume different kinds of data exposed from server’s end.
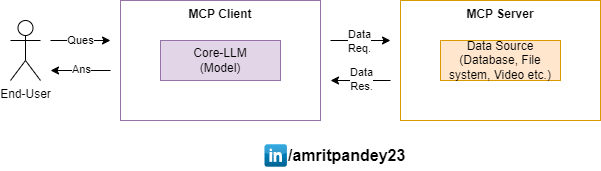
So, in summary MCP architecture comprise of two main components:
- Client: This is wrapper over the LLM service which will usually be the concern of LLM manufacturers or an LLM service provider(aka big tech). For example, Claude Desktop app has implemented MCP client which can work on with custom MCP servers.
- Server: This is a wrapper on top of a data source. Usually data-storage or data-source manufacturer would likely deal with this part. For example, Github already have implemented their official version of Github MCP Server.
A individual developer can also create their implementation of servers and clients but the real problem solved by MCP is to have open and extensible components that can provide standard list of tools, resources, prompts etc. to developers working on their AI use cases.
A hypothetical scenario
Let’s take a hypothetical scenario of developing AI application over Github as a data source.
Developers would start by creating their application: UI, backend, security etc. all the good stuff.
Then they’ll also write their data extraction logic from the Github APIs.
You can see the final arhicture of apps built by three different developer in the illustration below.
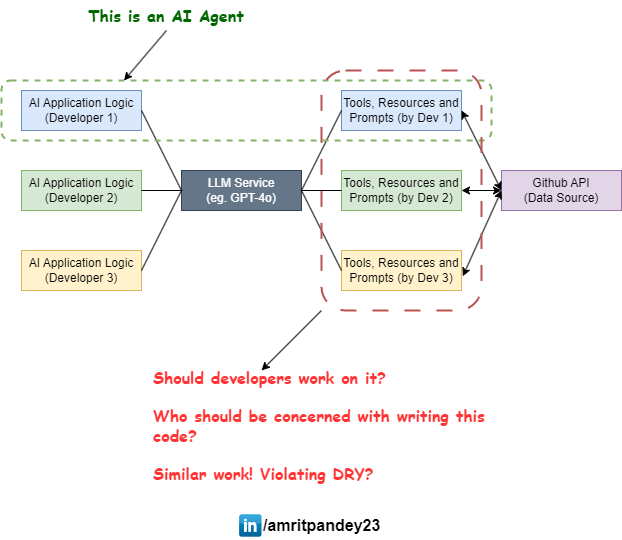
🤔 Assuming many developers work on such applications for their different use cases, does writing data source logic makes sense for all the developers?
We can ask following question:
- Should individual developers be concerned with writing data access logic?
- If not, then who should be concerned for providing data access logic?
- Does multiple developers working on same thing violets DRY?
👉 The most important part that each developer be concerned about should be the actual application logic and not the data read or creating tools to extract different sets of data.
✅ The data should be the realm of the data source manufacturers or teams solely working on providing data access, so that the standards can be maintained for all the developers making applications for different use cases.
A concrete solution
Shown below is an illustration that demonstrate how the separation of data source concern is taken up by the Github that provides a uniform interface to all kinds of MCP client.

LLM services now don’t need extra layer of configuration to work with the custom data fetching which each developer may have created otherwise.
👉 By wrapping the LLM services with an MCP client, the standards will be in place for the client to smoothly communicate with MCP servers to extract the exact data required according to the application needs.
Tying up everything together
As you can see below, how efficient the whole process becomes when we use MCP servers for our data needs.
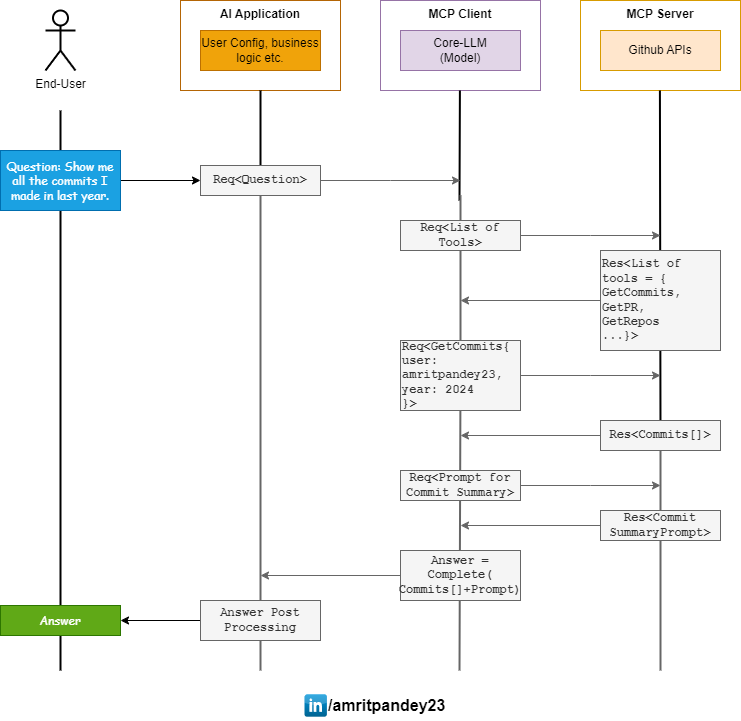
The MCP clients would know the exact request to make to gather data required for generation of answer. Developers no longer need to handle this part manually.
The collection of tools, resources, prompts, roots etc. all facilitate in a seamless data read manner.
🔗 More on the architure of can be read here.
NOTE: Some of the requests in this diagram are completely hypothetical. For example, requesting list of tools as a discovery step which is not thought of in the official implementation for now.
Who’s using MCP already?
- Development Tools Manufacturers: Zed, Replit, Codeium and Sourcegraph.
- 3-D Modelling software: Blender.
- Microsoft’s Co-pilot.
- Amazon’s AWS Bedrock.
- Anthropic’s Claude Desktop App.
- Github.
Resources to learn more about MCP
Model Context Protocol Clearly Explained | MCP Beyond the Hype
Model Context Protocol Overview – Why You Care!
What is MCP in AI? Model Context Protocol Simply Explained [No BS]
In conclusion we can say that, as for most of the things in software development standards are the default way to operate and AI seems to be taking the same route. Good thing is it is taking it sooner than later.
Subscribe to my newsletter today!

Very superb visual appeal on this site, I’d value it 10 10.